SmartStore introduces two key components: a remote storage tier and a cache manager. These components facilitate the distribution of data between the local indexer and the remote storage tier, with the cache manager residing within the indexer.
This system enables you to significantly reduce the storage requirements on the indexer itself, thereby affording you the flexibility to choose highly I/O optimized computing resources. The majority of your data is stored in the remote storage, while the indexer maintains a compact local cache. This cache primarily includes hot buckets, copies of warm buckets actively involved in ongoing or recent searches, and bucket metadata.
Furthermore, you have the flexibility to enable SmartStore for either all of your indexes or a selected subset, tailoring the approach to your specific needs.
Advantages of Splunk Smart Store
• You can significantly cut down on storage expenses by harnessing the cost-effective nature of remote object stores, as opposed to relying on expensive local storage solutions. Let’s look at AWS as a cloud Provider Amazon S3 pricing for first 50 TB / Month $0.023 per GB Next 450 TB / Month $0.022 per GB Over 500 TB / Month $0.021 per GB on the other hand the cost for Amazon EBS pricing for General Purpose SSD (gp2) $0.10 per GB-month. Switching to S3 alone can lead to impressive savings of up to 78% on your infrastructure costs. However, it's worth noting that Cloud Storage operates on a pay-as-you-use billing model. When procuring traditional infrastructure, there's often padding added to account for potential future needs. In the initial stages of deployment, it's quite uncommon to fully utilize the storage up to its padding limit. Taking all these factors into consideration, the potential for savings extends well beyond that initial 78%
• You gain access to robust high availability and data resiliency features provided by remote object stores
• Full recovery of warm buckets even when the number of peer nodes that goes down is greater than or equal to the replication factor.
• A bootstrapping capability that allows a new cluster or standalone indexer to inherit data from an old cluster or standalone indexer.
When not to consider for Splunk Smart Store
• If you run frequent long lookback searches, you might need to increase your cache size or continue to rely on local storage.
Note: if you have few reports and dashboards which need lookback search that data can be passed to a specific index which won’t use Splunk Smart Store as it is possible to implement Splunk Smart Store at index level.
Splunk Smart Store Architecture
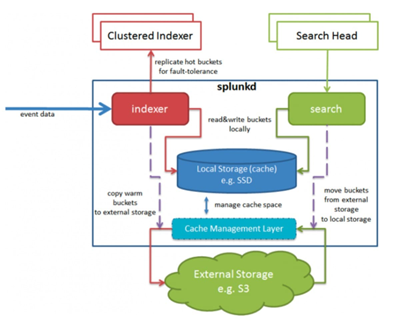
As you can see Splunk Smart Store have an ability to cache the data this caching allows Splunk Smart Store to keep the searches fast and
How Splunk Smart Store Benefited Us
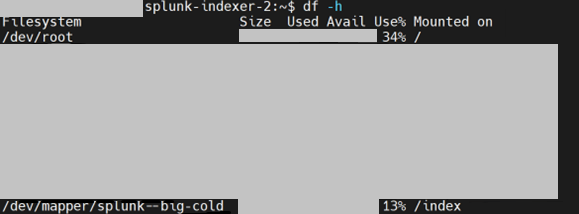
In our case after implementing Splunk Smart Store we were able to reduce our fast storage (which we use to store hot and warm buckets) from 72% to 34% and Slow Storage (which we use to keep cold buckets) from 73% to 13 %
Before Implementing Splunk Smart Store →
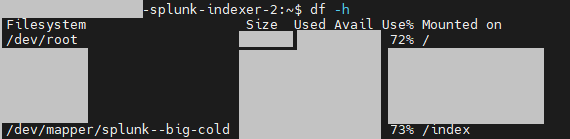
After Implementing Splunk Smart Store →